GPU Resource Descriptors
In the previous post I said this about descriptors
when it comes to managing them (descriptors) it is no different than ID3D12Heap. In fact, it gets easier here because descriptors are a fixed size structs, so when it comes to managing the offset, it is quite simple and can be done using a simple ring allocator. However, when we pair it with resource binding to the shaders, the process gets more intricate which we will take a look in the next blog.
But just for memory management for descriptors, it can be kept same as the resource heap with 4 separate descriptor heaps
So lets take a look at “how intricate” does it get.
When the GPU’s command processor encounters a draw call in a command buffer, it kicks off shader execution across thousands of threads. Each shader thread needs to know where to find its input data. The GPU needs this information in a format it can consume directly, with no driver intervention.
The shader itself is a compiled code running on the GPU’s shader cores. When the shader executes an instruction like texture.Sample(sampler, uv), that instruction contains a register number such as t0 for texture register 0. The GPU needs to translate that logical register number into a physical memory address where it can fetch texel data. This translation happens through the descriptor machinery.
Today, we take a look at the entire system and talk about how I like to manage the resource binding and descriptors in my engine.
Descriptor Data
Lets take a look at what a descriptor really is. Here is what MSDN says about it.
A descriptor is a relatively small block of data that fully describes an object to the GPU, in a GPU-specific opaque format. Descriptors vary in size, depending on the GPU hardware. You can query for the size of an SRV, UAV, or CBV by calling ID3D12Device::GetDescriptorHandleIncrementSize.
A descriptor in D3D12 is a small, well-defined block of data that lives in GPU accessible memory and tells the GPU hardware directly how to interpret and access a resource. As mentioned earlier, the GPU needs this information in a format it can consume directly, with no driver intervention, to allow minimum work done by the driver providing direct control and performance when rendering.
And since it is defined to be used directly by the GPU hardware. the driver does not track or hold references to them, it is up to the app to ensure the correct descriptor is in use.
Descriptor Handles
A descriptor handle is the unique address of the descriptor. It is similar to a pointer, but is opaque as its implementation is hardware specific.
In order to manage the descriptors on the application side, D3D (and other graphics APIs) gives an opaque pointer to the unique address of the descriptor created in the DescriptorHeap. And since the size of the descriptors varies per hardware, we need to query it using ID3D12Device::GetDescriptorHandleIncrementSize. To ensure that a pointer points to the correct descriptor for the said resource, we need this size to increment it properly in the application.
There are two different handles of the same descriptor based on the DescriptorHeapFlags.
typedef enum D3D12_DESCRIPTOR_HEAP_FLAGS {
D3D12_DESCRIPTOR_HEAP_FLAG_NONE = 0,
D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE = 0x1
};
FLAG_NONE indicates a CPU visible heap and FLAG_SHADER_VISIBLE indicates a both CPU and a GPU visible heap. To get a descriptor handle for the start of a heap, after creating the descriptor heap itself, call one of the following methods:
- ID3D12DescriptorHeap::GetCPUDescriptorHandleForHeapStart which returns a D3D12_CPU_DESCRIPTOR_HANDLE.
- ID3D12DescriptorHeap::GetGPUDescriptorHandleForHeapStart which returns a D3D12_GPU_DESCRIPTOR_HANDLE.
And it goes without saying that for a CPU only descriptor heap, the GPU handle would give an invalid address.
CPU handles are for immediate use, such as copying where both the source and destination need to be identified. GPU handles are not for immediate use, they identify locations from a command list, for use at GPU execution time. They must be preserved until any command lists referencing them have executed entirely.
To make it a little bit easier to store and increment the CPU and GPU handles, here is a small wrapper class that I borrowed from microsoft’s mini engine. A Descriptor Handle in my engine will always have both CPU and GPU pointer. For the CPU only descriptors, the GPU pointer will be INVALID_ADDRESS. And the wrapper class also has a few helper methods and importantly the + and += operator overloads for easily managing the increments.
#pragma once
#include "common.h"
#include "directx.h"
namespace graphics
{
/*
* This handle refers to a descriptor or a descriptor table(contiguous descriptors)
* A simple abstraction over CPU and GPU handles with helper functions and operator overloads to use them easily.
* The handle can be None(CPU Only) and Shader Visible(CPU and GPU both).
* And just like DescriptorHeapFlags, handles can never be GPU only.
*/
class DescriptorHandle
{
public:
static constexpr uint32_t INVALID_ADDRESS = 0xffffffff;
DescriptorHandle()
{
mCPUHandle.ptr = INVALID_ADDRESS;
mGPUHandle.ptr = INVALID_ADDRESS;
}
// Allows constructing handles that might not be shader visible.
DescriptorHandle(const D3D12_CPU_DESCRIPTOR_HANDLE cpuHandle)
: mCPUHandle(cpuHandle)
{
mGPUHandle.ptr = INVALID_ADDRESS;
}
DescriptorHandle(const D3D12_CPU_DESCRIPTOR_HANDLE cpuHandle, const D3D12_GPU_DESCRIPTOR_HANDLE gpuHandle)
: mCPUHandle(cpuHandle), mGPUHandle(gpuHandle)
{
}
DescriptorHandle operator+ (const INT offsetScaledByDescriptorSize) const
{
DescriptorHandle ret = *this;
ret += offsetScaledByDescriptorSize;
return ret;
}
void operator += (const INT offsetScaledByDescriptorSize)
{
if (mCPUHandle.ptr != INVALID_ADDRESS)
{
mCPUHandle.ptr += static_cast<const size_t>(offsetScaledByDescriptorSize);
}
if (mGPUHandle.ptr != INVALID_ADDRESS)
{
mGPUHandle.ptr += static_cast<const size_t>(offsetScaledByDescriptorSize);
}
}
inline bool operator ==(const DescriptorHandle& other) const
{
return (mCPUHandle.ptr == other.getCPUPtr());
}
inline bool operator !=(const DescriptorHandle& other) const
{
return (mCPUHandle.ptr != other.getCPUPtr());
}
inline size_t getCPUPtr() const { return mCPUHandle.ptr; }
inline uint64_t getGPUPtr() const { return mGPUHandle.ptr; }
inline bool isNull() const { return mCPUHandle.ptr == INVALID_ADDRESS; }
inline bool isGPUVisible() const { return mGPUHandle.ptr != INVALID_ADDRESS; }
const D3D12_CPU_DESCRIPTOR_HANDLE getCPUHandle() const { return mCPUHandle; }
const D3D12_GPU_DESCRIPTOR_HANDLE getGPUHandle() const { return mGPUHandle; }
// Operator overloads for implicit casts
const D3D12_CPU_DESCRIPTOR_HANDLE* operator&() const { return &mCPUHandle; }
operator D3D12_CPU_DESCRIPTOR_HANDLE() const { return mCPUHandle; }
private:
D3D12_CPU_DESCRIPTOR_HANDLE mCPUHandle;
D3D12_GPU_DESCRIPTOR_HANDLE mGPUHandle;
};
}
And same as the Heap class from the previous post, we have a DescriptorHeap class as a simple wrapper with a copyDescriptorsFrom().
#pragma once
#include "common.h"
#include "directx.h"
#include "Device.h"
#include "DescriptorHeapEnums.h"
#include "DescriptorHandle.h"
namespace graphics
{
/*
* A wrapper over ID3D12DescriptorHeap.
*/
class DescriptorHeap
{
public:
struct Description
{
std::string name;
DescriptorHeapType type;
size_t maxDescriptors;
DescriptorHeapFlags flag;
};
// Create and initialize the descriptor heap.
DescriptorHeap(Device& device, const Description& createDescription);
// Get the heap start handle
inline DescriptorHandle getHeapStart() const { return mHeapStart; }
// Calculates the heap offset of the handle.
inline uint32_t getOffsetOfHandle(const DescriptorHandle& dHandle) const
{
return static_cast<uint32_t>(getByteOffsetOfHandle(dHandle) / mDescriptorSize);
}
// Calculates the heap offset in bytes of the handle.
inline uint32_t getByteOffsetOfHandle(const DescriptorHandle& dHandle) const
{
return static_cast<uint32_t>((dHandle.getCPUPtr() - mHeapStart.getCPUPtr()));
}
// Batched copy of descriptors into this heap from one or more source ranges.
void copyDescriptorsFrom(Device& device, const DescriptorHandle& destStart,
const std::vector<DescriptorHandle>& srcStarts,
const std::vector<unsigned int>& srcCounts);
// Checks for three conditions.
// - Whether the handle falls inside the range between firstHandle and heapSize
// - Whether the handle type matches with the HeapFlag
// - If descriptor is GPUVisible then whether the GPU offset and CPU offset matches.
bool validateHandle(const DescriptorHandle& dHandle) const;
// Frees the heap.
// Since mHeap is a ComPtr the heap is released automatically.
virtual ~DescriptorHeap();
public:
// Return descriptor max descriptors size.
inline size_t getMaxDescriptors() const { return mMaxDescriptors; }
// Return descriptor handle increment size.
inline size_t getDescriptorSize() const { return mDescriptorSize; }
// Return descriptor heap type.
inline DescriptorHeapType getDescriptorHeapType() const { return mType; }
// Returns the raw pointer of ID3D12DescriptorHeap.
inline ID3D12DescriptorHeap* get() const { return mHeap.Get(); }
inline ID3D12DescriptorHeap* get() { return mHeap.Get(); }
// Operator overload that returns the raw pointer of ID3D12DescriptorHeap.
inline const ID3D12DescriptorHeap* operator->() const { return mHeap.Get(); }
inline ID3D12DescriptorHeap* operator->() { return mHeap.Get(); }
protected:
const size_t mMaxDescriptors;
const DescriptorHeapType mType;
// Queried from device via GetDescriptorHandleIncrementSize
size_t mDescriptorSize;
// Heap start handle.
DescriptorHandle mHeapStart;
private:
Microsoft::WRL::ComPtr<ID3D12DescriptorHeap> mHeap;
};
}
A CPU descriptor handle is essentially a pointer into system memory where the descriptor lives from the CPU’s perspective. This handle is used to copy or create new descriptors. A GPU descriptor handle is a GPU virtual address that points to where that descriptor lives in GPU-accessible memory. This is what gets passed to SetGraphicsRootDescriptorTable, and here we only pass the handle that points to the beginning of the descriptor table, meaning that whenever we bind resources, the GPU descriptors must be contiguous.
So to give a high level overview of what I like to do is:
- There will always be only one CPU and GPU heap because we know that creating and setting any ID3DPageable takes a lot of time.
- When creating any resource descriptor, I always create it on CPU heap. This way, the CPU descriptor heap can be a little bit larger in size and the CPU descriptors can stay disposable with a simple ring allocator.
- And at the time of creating the root signature, I allocate the required number of descriptors in GPU heap. This way, I have the exact layout of what the shader will expect and what type of resources does it need, this is to prevent unnecessary allocations in the GPU heap and to ensure maximum reuse of the descriptors.
- And the render pass can then decide when to copy the descriptors from the CPU heap to the GPU heap. The reason why this control is on the render pass is because there will be certain resources that will never change after its creation, while some resources might change during certain events such as resize. The
copyDescriptorsFrom()in the DescriptorHeap class assists in this and provides a quick way to perform a batch copy of scattered descriptors using ID3D12Device::CopyDescriptors method. - And since D3D requires us to call
setDescriptorTablebefore a draw call, the render pass also decides when to do the same.
DescriptorHeapWithAllocator
Same as the HeapWithAllocator class from the previous post. a DescriptorHeapWithAllocator with these categories
enum DescriptorsCategory
{
StaticGPU,
DynamicCPU,
DynamicGPU,
RenderTargetCPU,
DepthStencilCPU,
COUNT
};
- StaticGPU: is the section of the GPU visible heap of CBV_SRV_UAVs for the resources that do not change at render time.
- DynamicCPU: all the CPU descriptors are disposable and are expected to change.
- DynamicGPU: the section of the GPU heap where the resources are expected to change
- RenderTargetCPU and DepthStencilCPU: is separate heap for RTVs and DSVs
A trivial and common ResourceManager class that owns both the resource and descriptor heaps provides helper methods to stores resources, descriptors and resource tables in hash maps to ensure quick and easy access (and reuse) using string IDs. Here, the resource manager can be requested to create N number of resource views (descriptors) of a said resource with a unique string ID. And all of those resource views will be stored in the CPU heap.
Shader Inputs and Resource Tables
To achieve what we discussed above, my system is split into two important classes.
Resource Tables denotes a contiguous allocation of descriptors. It needs a pre allocated allocationStart handle, meaning that it can represent both CPU and GPU table. This is also the same class that represent a descriptor table that we bind before draw call. It expects a table layout where it has simple entries consisting of the RangeType ie CBV, SRV, UAV, Sampler; and a shader visibility flag ie VertexShader, HullShader, DomainShader, etc.
/*
* Resource Table represents a descriptor table.
* It needs a pre allocated allocationStart handle, meaning that it can represent both CPU and GPU table.
*/
class ResourceTable
{
public:
// Descriptor Table Entry
struct Range
{
const DescriptorRangeType type;
const unsigned int count = 1;
};
// Descriptor Table
struct Layout
{
const ShaderVisibility shaderVisibility;
const std::vector<Range> ranges;
};
ResourceTable(const Layout& layout, DescriptorHandle allocationStart);
inline const Layout& getLayout() const { return mLayout; }
inline const DescriptorHandle& getHandleStart() const { return mDescriptors; }
inline unsigned int getHandlesCount() const { return mDescriptorsCount; }
// Set a resource descriptor at the specified row and column
void setResource(Device& device, const DescriptorHandle& descriptor,
const unsigned int row = 0, const unsigned int column = 0);
void copyDescriptorsFrom(Device& device, const ResourceTable& table);
private:
unsigned int getDescriptorOffsetAt(const unsigned int row, const unsigned int column) const;
private:
const Layout mLayout;
DescriptorHandle mDescriptors;
unsigned int mDescriptorsCount;
};
And, using the ResourceManager class, this is how a ResourceTable would be created. The resource manager maintains a hash map where the resource table will be stored with ID MyShader_ResourceTable. This is to allow other render passes to reuse the same resources without going through the entire process. However, I am yet to design robust a system for managing these IDs, and right now providing a unique string ID manually is definitely prone to human errors.
mStaticShaderResourceTableLayout{
graphics::ShaderVisibility::Vertex | graphics::ShaderVisibility::Pixel,
{
{graphics::DescriptorRangeType::CBV, 1}, // Common Params Buffer
{graphics::DescriptorRangeType::SRV, 1}, // Resource Buffer
}
};
mShaderResources(
resourceManager.createResourceTable(
"MyShader_ResourceTable",
mStaticShaderResourceTableLayout,
graphics::DescriptorHeapWithAllocator::DescriptorsCategory::StaticGPU
)
);
And later the render pass can call the SetResource(), which internally copies the CPU descriptor from the resource manager to the GPU descriptor of the mShaderResources.
mShaderResources.setResource(
device,
resourceManager.getByteAddressBufferCBV("CB_CommonPassParams_RenderPass"),
0
);
mShaderResources.setResource(
device,
resourceManager.getStructuredBufferSRV("SR_ResourceBuffer"),
1
);
ShaderInput is where we create the root signature based on the input layout. The layout is expected in order of shader registers. But here, this restriction works in our favor because the ShaderInputs are meant to be created by the render passes and the passes are expected to know the shader, indirectly ensuring that the layout mismatch never happens.
It also keeps track of all the root signatures in a hash map and reuses an existing one if the layout is the same. And It expects GPU resource tables which can be directly used to set as root descriptor tables.
The constructor creates a root signature for this particular ShaderInput’s layout and it generates a unique string ID based on the layout so that if other render pass needs the same layout, then the same root signature can be reused.
The intent behind keeping this hash map separate from the ResourceManager is that this is not directly related to “resources”; while the ResourceTable mentioned earlier is something that can be directly related to the resources created via the resource manager. An example would be to create a fat ResourceTable of all the resources and using it in a bindless model.
The finalize() calls the setDescriptorTable whenever called from the render pass.
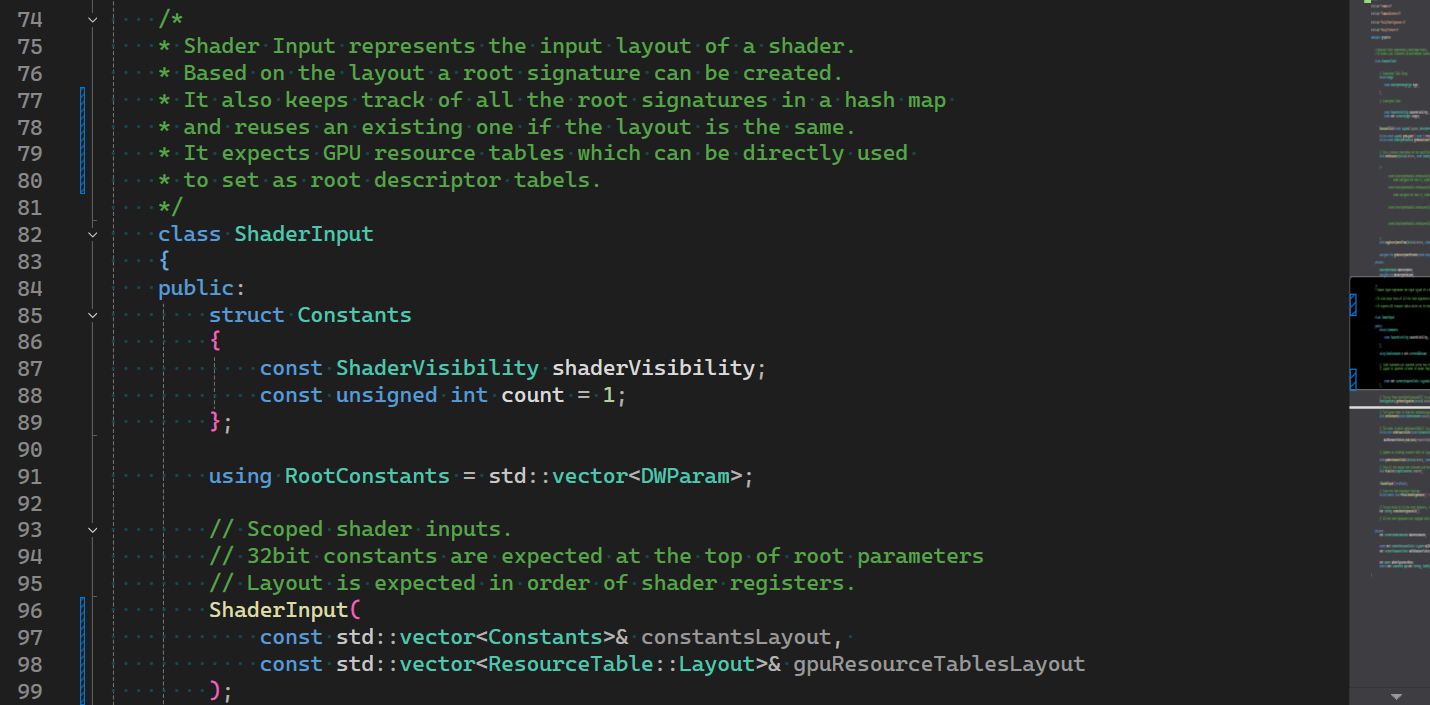
/*
* Shader Input represents the input layout of a shader.
* Based on the layout a root signature can be created.
* It also keeps track of all the root signatures in a hash map and reuses an existing one if the layout is the same.
* It expects GPU resource tables which can be directly used to set as root descriptor tabels.
*/
class ShaderInput
{
public:
struct Constants
{
const ShaderVisibility shaderVisibility;
const unsigned int count = 1;
};
using RootConstants = std::vector<DWParam>;
// Scoped shader inputs.
// 32bit constants are expected at the top of root parameters
// Layout is expected in order of shader registers.
ShaderInput(const std::vector<Constants>& constantsLayout, const std::vector<ResourceTable::Layout>& gpuResourceTablesLayout);
// Get or Create a root signature for the specified layout.
// The key from createRootSignatureID() is used to get or create from the hash map.
RootSignature& getRootSignature(Device& device);
// Stages constants for root signature.
// The layout index is from the constantsLayout.
void setConstants(const RootConstants values, const unsigned int layoutIndex);
// Stages a GPU resource table for root signature.
// The order in which setResourceTable() is called determines the layout index.
inline void setResourceTable(const ResourceTable& resourceTable)
{
mGPUResourceTables.push_back(resourceTable);
}
// Updates an existing resource table at layoutIndex.
// This makes use of Device::CopyDescriptors().
void updateResourceTable(Device& device, const ResourceTable& resourceTable, const unsigned int layoutIndex);
// Sets all the staged root constants and descriptor tables.
void finalize(GraphicContext& context);
void finalize(ComputeContext& context);
~ShaderInput() = default;
// Clear the root signature hash map.
inline static void freeAllRootSignatures() { ShaderInput::msRootSignatures.clear(); }
private:
// To keep track of all the root signature, it creates a string key based on layout which is used for hash map.
std::string createRootSignatureID();
// All the root signatures are equipped with 6 static samplers.
static const std::array<StaticSampler, 6> getStaticSamplers();
private:
std::vector<RootConstants> mRootConstants;
const std::vector<Constants> mConstantsLayout;
const std::vector<ResourceTable::Layout> mGPUResourceTablesLayout;
std::vector<ResourceTable> mGPUResourceTables;
private:
std::mutex mRootSignatureMutex;
static std::unordered_map<std::string, RootSignature> msRootSignatures;
};
So, here is how a render pass would create and use a ShaderInput
mRenderPassSI(
{ {graphics::ShaderVisibility::Vertex, 4} }, // Frame Constants
{ mStaticShaderResourceTableLayout }
);
// ...
psoDesc.rootSignature = &(mRenderPassSI.getRootSignature(device));
// Render()
mRenderPassSI.setResourceTable(mShaderResources);
context.setRootSignature(mRenderPassSI.getRootSignature(context.getDevice()));
mRenderPassSI.setConstants(
{ frameConstants.totalTime, frameConstants.deltaTime },
0
);
mRenderPassSI.finalize(context);
// ...
context.drawInstanced(4, 10000);
Conclusion
This is one of those systems that can be over engineered to the extremes and still sometimes feel insufficient. But this simple implementation gives me a reusable and easy system that prevents a lot of human errors. Microsoft’s Mini Engine also implements a very well designed class for a similar-ish descriptor management in a class names DynamicDescriptorHeap. However, the difference between mini engine and my engine is that mini engine derives the layout and creates descriptor tables from the root signature itself, while I create the root signature and descriptor table using a same layout. So the code there seems tightly coupled compared to this system.
If you have any suggestions or comments and you like this post or you want to learn more, lets connect on twitter @JayNakum_ or linkedin @JayNakum.
Thanks for reading, Aavjo!
© 2026 Jay Nakum. All rights reserved.
Any direct or indirect use of all content requires prior written permission. No AI training allowed.